|
I am an Applied AI Researcher at Zepp Health. My recent work on Nutrition and Web Agents was demoed at CES 2025 [media coverage]. I'm primarily interested in multimodal learning, LLMs/Agents and visual scene understanding. I completed my Master's degree from Mila and Université de Montréal. During my graduate studies, I was fortunate to have worked with Ruohan Gao (Meta), Prof. Mohamed Elhoseiny (KAUST) and Prof. Dinesh Manocha (UMD). I am also grateful to have collaborated with Senthil Yogamani (Qualcomm), Prof. Ciarán Eising (U.Limerick) and other wonderful researchers at Qualcomm and Valeo AI. Previously, I worked under the guidance of Prof. Ujjwal Bhattacharya at the CVPR Unit, Indian Statistical Institute, Kolkata. Earlier, I have also completed a short stint at Bhabha Atomic Research Center, Mumbai where I worked on Devanagari text recognition in limited-data settings. I graduated from Amity University with a First Class with Distinction Bachelor's degree in Computer Science and Engineering. My prior research experience has been on audio-visual co-segmentation, audio-visual summarization and medical signal processing. Email / Google Scholar / Linkedin / Twitter / Github |

|
|
[Jul '25]: AVTrustBench is accepted at ICCV 2025! Check here! [Jul '24]: Meerkat is accepted at ECCV 2024! Check here! [Jul '23]: AdVerb is accepted at ICCV 2023! Check here! [Jul '23]: UnShadowNet is accepted in IEEE Access journal! [Sep '22]: Joined Mila as a Master's student. The program is supervised by Prof. Yoshua Bengio. [Nov '21]: Presented AudViSum at BMVC 2021! [Presentation] [Oct '21]: AudViSum accepted at BMVC 2021! [Sep '21]: Presented Listen to the Pixels at ICIP 2021! [Presentation] [May '21]: Listen to the Pixels accepted at ICIP 2021! [Jan '21]: Presented CardioGAN at ICPR 2020! [Presentation] |
|
|
|
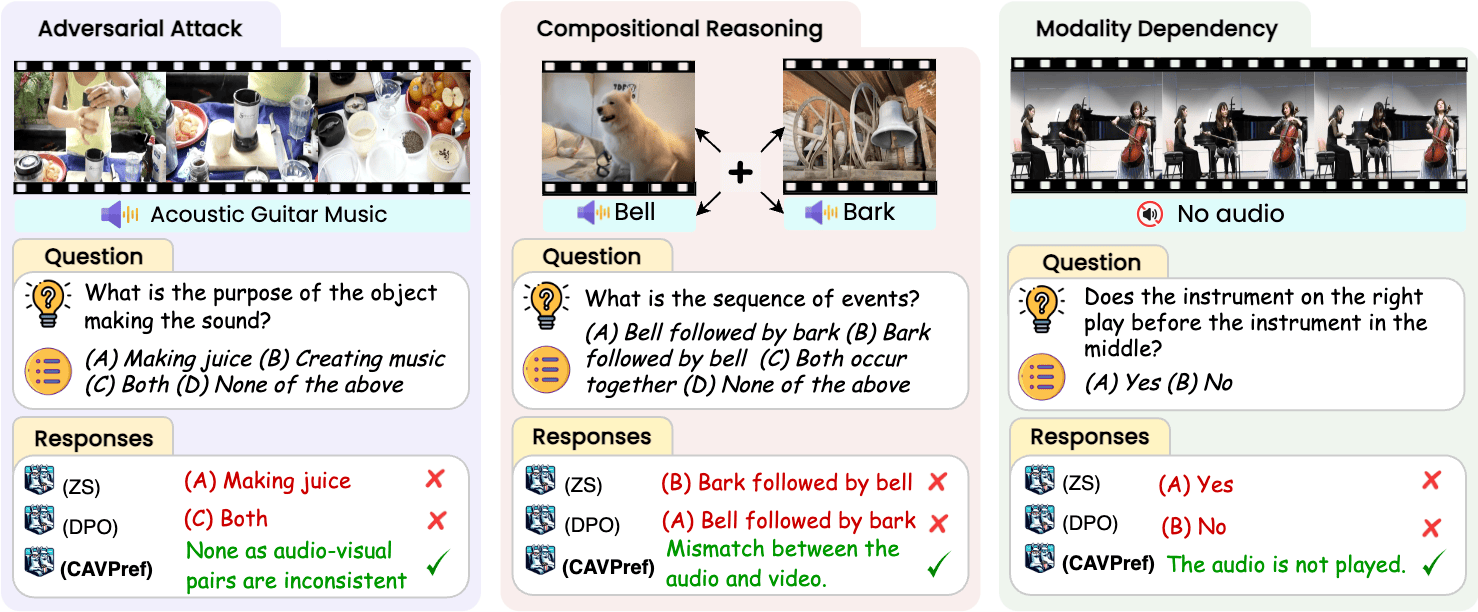
Sanjoy Chowdhury*, Sayan Nag*, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha ICCV, 2025 Code / Dataset / Website / BibTex We introduce AVTrustBench as a comprehensive 600K-sample benchmark evaluating AVLLMs on adversarial attacks, compositional reasoning, and modality-specific dependencies. We further propose a new model-agnostic calibrated audio-visual preference optimization-based training strategy, CAVPref, that improves performance of existing AVLLMs by up to 30.19%. |
|
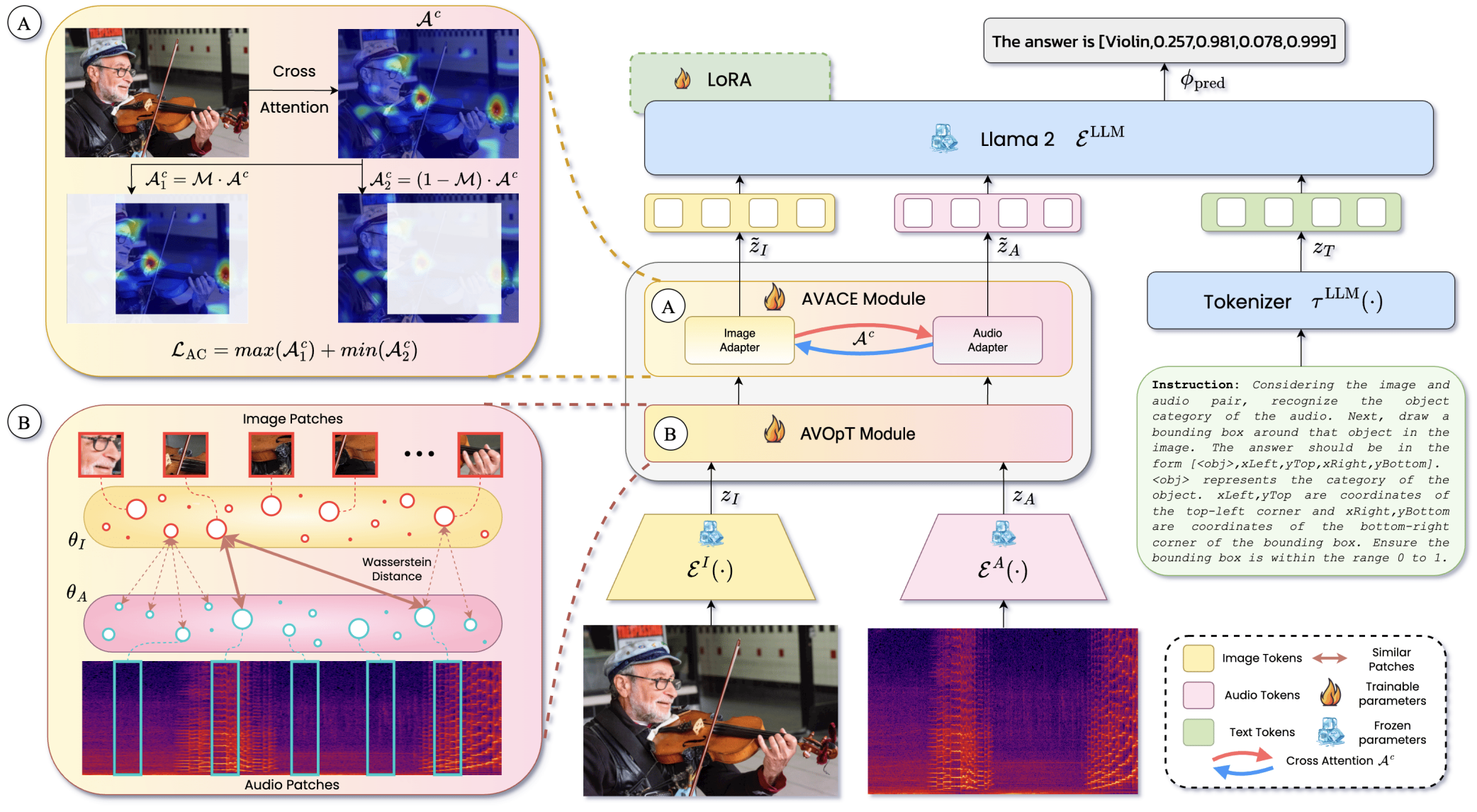
Sanjoy Chowdhury*, Sayan Nag*, Subhrajyoti Dasgupta*, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha ECCV, 2024 Code / Dataset / Website / BibTex We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT-3M that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. |
|
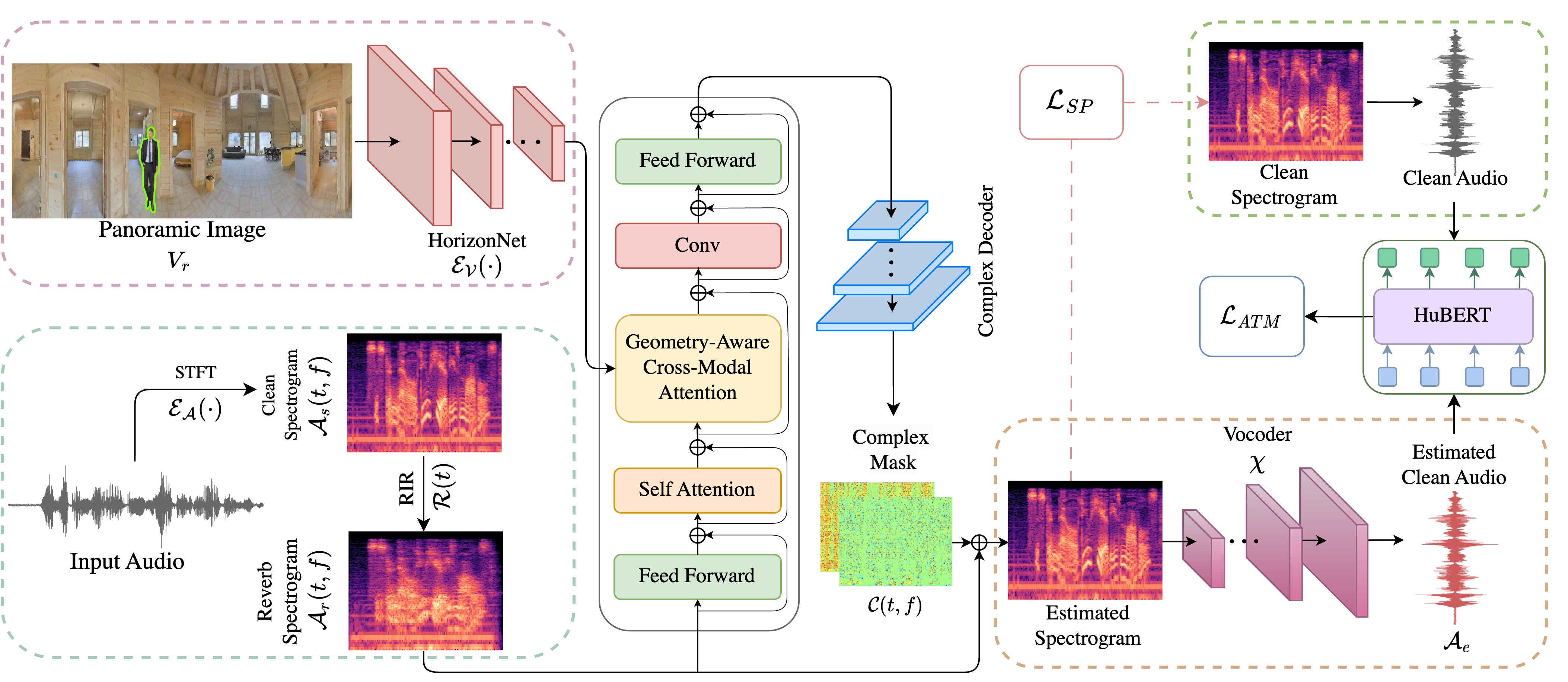
Sanjoy Chowdhury, Sreyan Ghosh, Subhrajyoti Dasgupta, Anton Ratnarajah, Utkarsh Tyagi, Dinesh Manocha ICCV, 2023 Code / Website / BibTex AdVerb leverages visual cues of the environment to estimate clean audio from reverberant audio. For instance, given a reverberant sound produced in a large hall, our model attempts to remove the reverb effect to predict the anechoic or clean audio. |
|
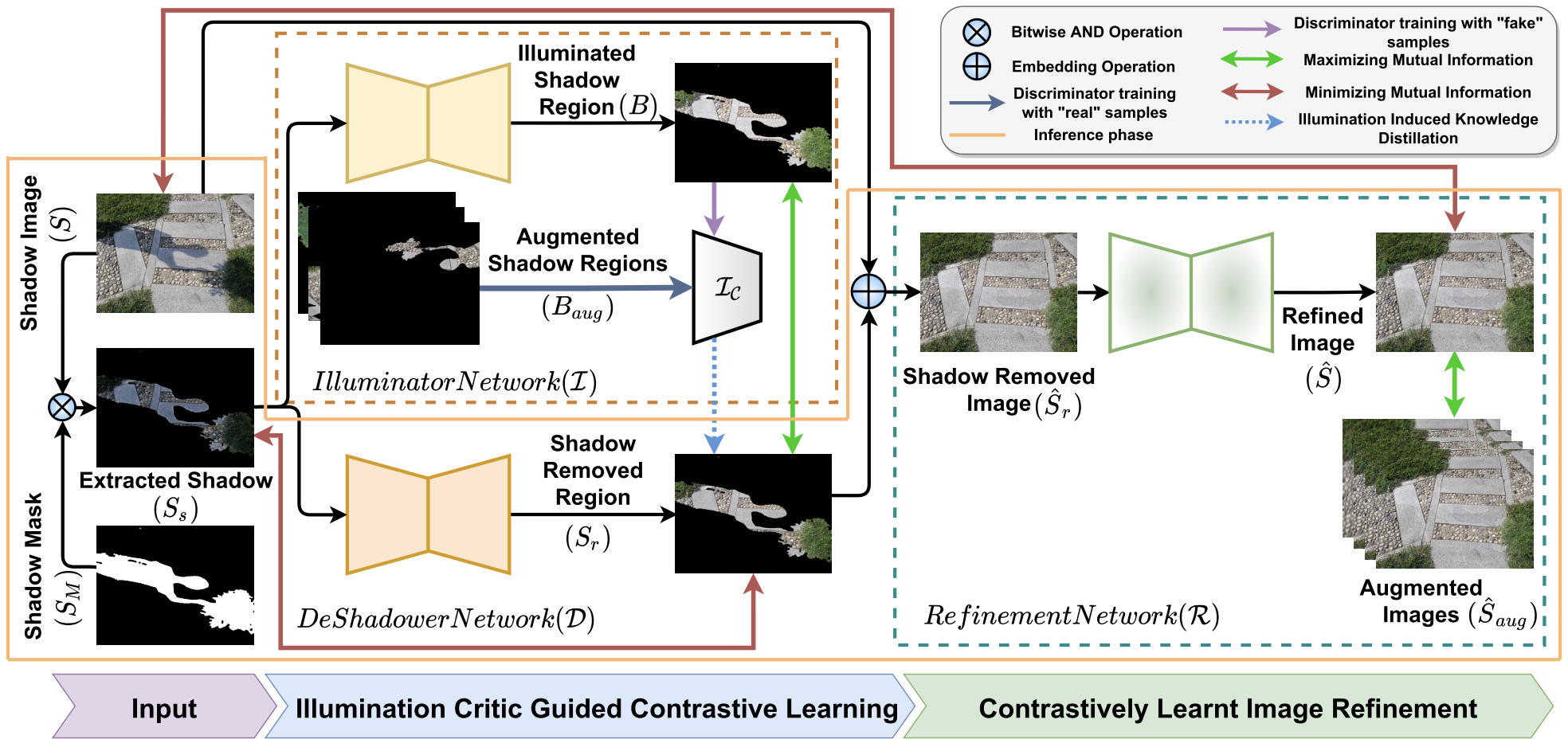
Subhrajyoti Dasgupta, Arindam Das, Senthil Yogamani, Sudip Das, Ciarán Eising, Andrei Bursuc, Ujjwal Bhattacharya IEEE Access Paper / BibTex Shadow removal is a hard task given the challenges associated with it, one of them being unavailabilty of paired labelled data. We propose a weakly supervised, illumination critic guided method using contrastive learning for efficiently removing shadows. |
|
Sanjoy Chowdhury, Aditya P. Patra, Subhrajyoti Dasgupta, Ujjwal Bhattacharya BMVC, 2021 Code / Presentation / BibTex Generating representative and diverse audio-visual summaries by exploiting both the audio and visual modalities, unlike prior works. Also presented a new dataset on TVSum and OVP with audio and visual annotations. |

|
Sanjoy Chowdhury, Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya ICIP, 2021 Code / Presentation / BibTex Audio-visual co-segmentation and sound source separation using a novel multimodal fusion mechanism, also addressing partially occluded sound source separation and co-segmentation for multiple but similar sound sources. |
|
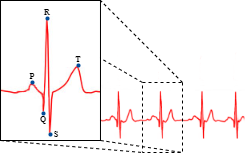
Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya ICPR, 2020 Presentation / BibTex Generating synthetic ECGs, for easy sharing without risk of privacy breach, using an Attention-based Generative Adversarial Network. |
|
|

|
While there exists large literature to detect and recognise English text in natural scenes and documents, during the time of this study, regional languages were not very largely studied. In this project done at Bhabha Atomic Research Center, Mumbai, dealt with a huge shortage of data and the nuances in the Devanagari script. Learning strategies for constrained settings like few-shot learning, transfer learning were used to develop the project. The project was implemented using Keras and Python. A great deal of OpenCV, Matplotlib and other scientific tools were also used. Code |

|
A humongous amount of data is produced by the LHC per day. This data needs to be processed and used efficiently for further research. This study was on how Machine Learning can be implemented for particle identification, particle track reconstruction, clustering of particles based on similarity, and identifying rare decays. A study on the proposed SHiP experiment, with the scope of Machine Learning in it, was also done. |
|
I often like to go out with my camera to cover music festivals, capture people and moments. Check out my works on 500px. Besides, I like indulging in a wide variety of movies and music. I keep a huge collection of movies from Kubrick to Nolan, Bergman to Ray. |